この記事を書き終えた後には
HBaseをシステムに組み入れるかどうかの判断をするための知識
が備わっていることを目的として執筆します。
Contents
まずはHBaseとは大きくハイレベルで捉えると何や?
一言でいうと、
メーッチャでかいテーブルを扱えるようにしました!!、といNoSQLの一つです
どれくらいでかいかっというと、数十億行 数百万カラム くらい想定していて、googleのbigtableをベースに設計されたよう。
最初に言っておくと、bigtableのシンプルな説明が全てを説明している
A Bigtable is a sparse, distributed, persistent multidimensional sorted map.
というもので、それらの意味が細かく分かれば、もう君は大丈夫。(ここ、本記事でも何ども参照する記事)
ちなみに、それを一般的なサーバーで構築できるとのこと。
例えるならばGoolgleのGFS(google file system)をBigtableが使いやすくするように。HBaseはHadoopやHDFSにたいしてのBigtableと捉えてくらはい。
するとますますbigtableについての理解が必要ではないか!?
とこもgoogle bittableの冒頭を読んだまでにすぎないですが、bigtableって分散ファイルシステム(GFS, HDFSとか)ってあくまでファイルで保存されているだけやん、
それをおなじみのSQLみたいに取り出せたら便利やん、もちろんMapReduce的なアプローチもあるんやけど、とにかう、そういうの必要でそれを幅広く(データサイズもlatency)やってくる
のがbigtableです。
こういうの本家の説明を読むべきで。よると、
直接的にスケールできるし、モジュール構成になっててデザインもいけてるで
一貫性のあるcap性のread/write できる
テーブルのシャーディング(断片化・分散化)が自動だし、設定可能
データセンターまたいでのサーバーのfailoverできて
HadoopのMapReduceがHbase tablesでできるよにもしております
うちのJava APIは使いやすいですし
リアルタイム性のqueryのためのBlock cacheとBloom Filters (現段階では意味不明)
ThriftゲートウェイとREST-fulなwebサービスで、なんやプログラマティックに操作可能っつう事ね、言いたいのは。
jruby-baseのREPLあるんだって
システム情報をHadoop matricsサブシステム通して, gangliaftとかJMXとかでみれたりもするぞ。
と長ーくなりましたが、こんな特徴です。
代用品は何か?
ここまで書いてると、bigtableとなるわな。ちなみにbigtableのストレージはGFSです。(後半まで読むと何を言っているのかが分かると思います。)
あとはcassandraも同じくカラム型のKVSですよね。コンセプトがちょっと違うのと、ストレージもちがうね。
Hbaseをシステムにくみいれるかどうかの判断はどのようにすれば良いか?
Hbaseの良さって,小さいデータセットに高速にアクセスできること。(この辺のquoraとかstackoverflowは読んでいると勉強になる)
HDFSってwrite onceっていうコンセンプトなんで
Hbaseで上書きとかしたい場合は、hbaseだとMemStoreとWALのおかげでwriteが速いといメリットはある。
特定のキーだけ取り出して、という用途が多発する。
バージョニングを管理したいデータがある。
あとは他の人の比較も参考にする
HBase導入時の検討項目と推奨構成、および設計ノウハウ や、facebookでもメッセージングに採用していたりとか。
カラム思考とは?
カラム型思考なんて
かたいこと言わずに、
「行に全部ぶち込んだだけ」
っておぼえてしまおう。するとアクセスコントロール(権限)とかの話もでてくるんで
ある程度データをまとるColumn familyっていう単位をつくっただけ。
NoSQLなので基本joinとかないので、データはすでにjoinされた状態でひたすら
rowkeyに突っ込まれると考えた方がよいだろうか。
あと、Hbaseにおいて最も重要な事実、それは
Hbaseは"rowkey"によってデータを保存し、それはprimary indexでもある。
そして、それらはソートされて保存される。
このrowkeyがプライマリーでソートされている事実は、Hbaseの根幹でHbaseスキーマデザインにも
関わっている。
Column Familyにはいるcolumnは物理的になれべて配置される。これはパフォーマンスのためである。
https://hbase.apache.org/book.html#datamodel
タイムスタンプは、RegionServerにデータが書き込まれた時のtsが値と一緒に保持される。
こうすこし詳しく見ていくなら、この記事もすばらしい(ちょうど、本家ののここで褒められていた記事だからね)
(big)Tableとか(H)baseとかRDBMSになれた頭には紛らわしいわ!
あらためてHbaseはOrderDictを分散された奴と言える
ソートされているのはあくまでrowkeyで値ではない。
唯一、versioningはある意味ソートされているとかんがえてもよいだろう。
最終的な例がわかりやすい。結局、hbaseのデータ構造は、こんな感じで、aaaaaがrowkeyね。Aがcolumn-familyですよ。そしてfooとかがqualiferつまりcolumnです。その下の15とか4はtimestampです。おそくらもうちょっと凝った感じにしないと、すんなりO(1)でトップのtimestampのデータにアクセスできませんが、基本はこのイメージでOK (https://dzone.com/articles/understanding-hbase-and-bigtab)
{
// ...
"aaaaa" : {
"A" : {
"foo" : {
15 : "y",
4 : "m"
},
"bar" : {
15 : "d",
}
},
"B" : {
"" : {
6 : "w"
3 : "o"
1 : "w"
}
}
},
// ...
}
アーキテクチャー
アーキテクチャーはこんな図にで表すことができます。
マスター、スレーブアーキテクチャーであることがわかります。
RegionServerはまぁ、ノードのことで、スレーブのことです。
RegionServerは Regionとよばる範囲のデータを保持していて、内部的なストレージはHFDSです。
緑で囲っている部分、HDFSとNameNodeはHDFSのコンポです。
ZookeeperはHbaseスレーブの状態を管理するに使われます。
なので、純粋なHBase製のコンポはスレーブ(RegionServer)とHMasterだけすね。
HmasterはRegionの管理とDDL(テーブル作成、削除)などのオペレーションはmaster経由でおこなわれます。
結構な重要な人ですね(、それゆえ可用性が完全ではないのです。)
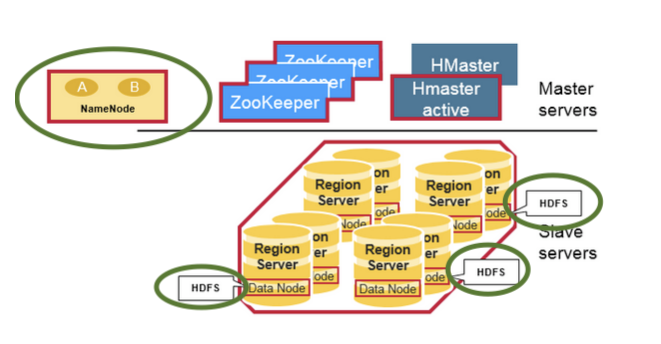
出典: https://stackoverflow.com/questions/16929832/difference-between-hbase-and-hadoop-hdfs, https://mapr.com/blog/in-depth-look-hbase-architecture/
データの読み書きの仕組み
読む仕組みは
Client: まずはZookeeperにKey_XXXにアクセスしたいだけど
Zookee: あ、それならRegionServerひろ子がしってるよ(MetaTable持ってる)
Client: RegionServerひろ子さん、Key_XXXにアクセスしたいだけど
Region: (ひろ子)はい、MetaTableによるとその範囲ですと、RegionServerたかしさんにありますね
Client: RegionServerたかしにKey_XXXで値を取得
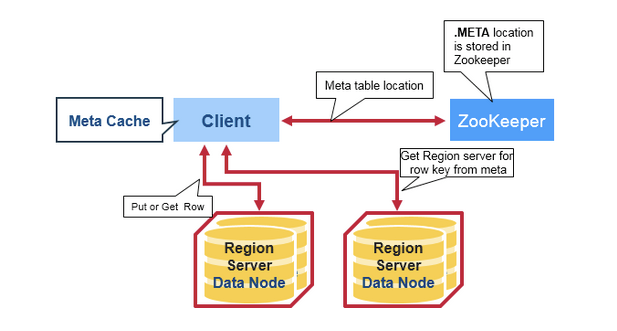
出典: https://mapr.com/blog/in-depth-look-hbase-architecture/
書く仕組みはWAL(WriteAheadLog)とよばれるログにこのしながらWriteを実行する仕組みで書かれます。
HBaseにおいては
RegionServerでは、RegionはMemostoreとしてメモリ上に展開されています。しかし、Memostoreの時点ではレプリケーションされておらず、さらにメモリ上だけではServerが落ちたときにデータをロストしてしまいます。そこでHBaseでは、変更内容をHLogとしてDiskに書き込むようになっています。このような仕組みを一般的にはWAL(WriteAheadLog, ログ先行書き込み)といいます。
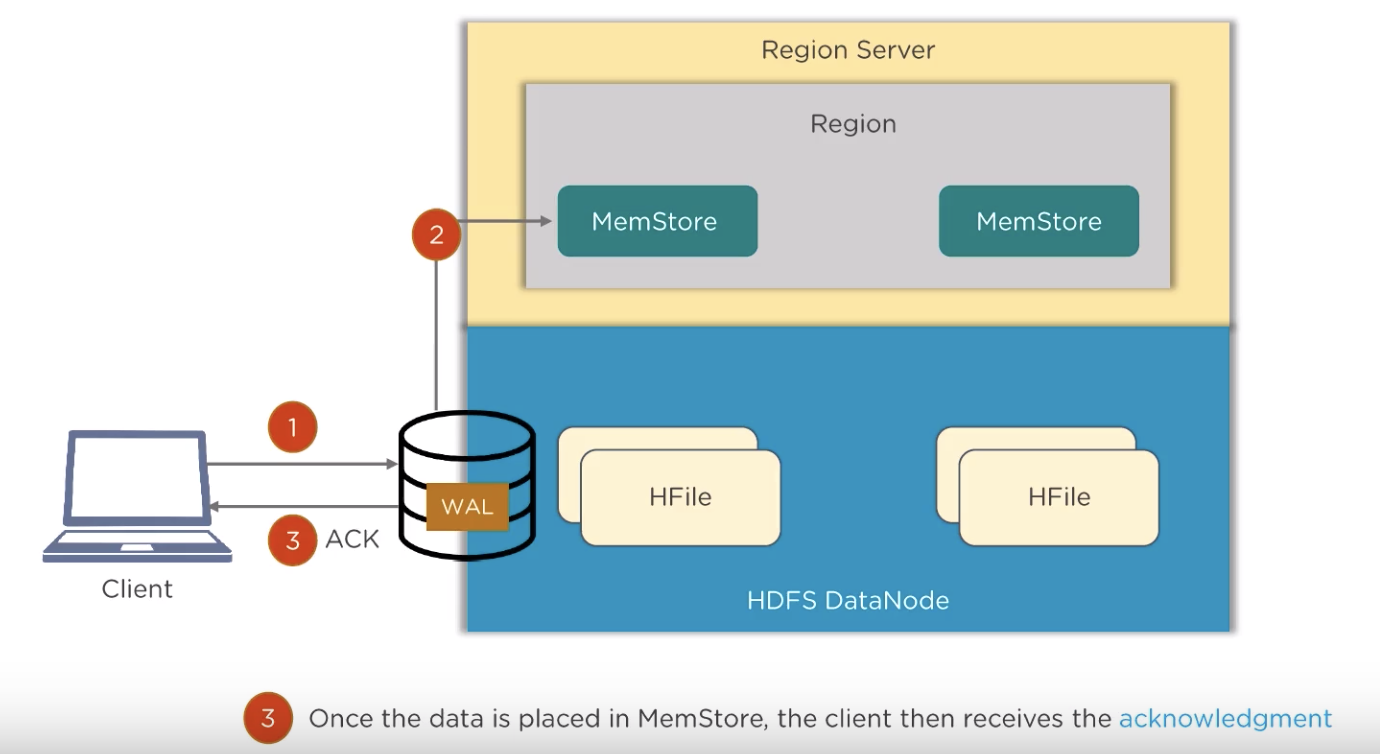
上図出典: https://www.youtube.com/watch?v=V1fXSCASVDc
こちらは動画で読み書きが説明されているところへのリンクです
なぜ速いのか?速いのは検索だけ!?
なんで、Hbaseは早いのかは、
このRegionの中でMetaStoreとうオブジェクトにまぁ、辞書だな。これが
キーがソートされた状態で管理されます。
それをHFileに定期的にダンプするし
HFileはさらにそれにB+treeにたいにindexつける
だからキーの検索は早いんです。
https://mapr.com/blog/in-depth-look-hbase-architecture/
あとは、diskへの書き込みもシーケンシャルでdiskヘッドの移動が起こらない工夫があるそうです。
もっと細かい説明がみたいかたは、こちらを参考にしてみてください。
スキーマ設計時の注意点
1、column familiyは最初に決めておけ!
理由は高いから ((big)Tableとか(H)baseとかRDBMSになれた頭には紛らわしいわ! より)
A table's column families are specified when the table is created, and are difficult or impossible to modify later. It can also be expensive to add new column families, so it's a good idea to specify all the ones you'll need up front.
2、カラムの操作はfull-scanが要るけど、column familyは前述のように事前定義でstaticだからO(1)で走査できる
In this case, the "zzzzz" row has exactly one column, "A:catch_phrase". Because each row may have any number of different columns, there's no built-in way to query for a list of all columns in all rows. To get that information, you'd have to do a full table scan. You can however query for a list of all column families since these are immutable (more-or-less).
3、columnとかにsecondary-indexとかないからね。あくまでrowkeyがprimary indexなるだけだから。
そうなると、columnに突っ込んだものをcolumn family 単位でソートとかしない方がいい。どんどん突っ込んでversionニングで管理させるのがよいか。ここは、ちょっとまだよくわかってないです。
4、colum familyは10個以下にしておこう
根拠は?このブログが言ってました。https://dwgeek.com/hbase-table-schema-design-concept.html/ 自分に経験値がないので経験値の高い人の意見を仮説として進めばいい。間違いだったら修正・軌道修正するだけ。もちろん事前にこれを前提としてこけた時のリスクくらいは考えてから乗っかろう。
5、rowkeyの設計のキモはいかにバランスよくnodes感で分散されるか。
Hbaseはrowkeyでソートされた巨大なdictionaryだ。
rowkeyにインクリメンタルなidとか使うと偏っちゃんんで、hashing使うとか。初期のcrawerのドメイン別とか、うまいことすでに分散されている文字列をつかうとか。
参考:https://dwgeek.com/hbase-table-schema-design-concept.html/
FAQ
hbaseってなんでHadoopとセットでつかわれるの?
hbaseが Column思考のNoSQLであることは、わかりました。だったらCassnadraと同じですね。でも
なぜhadoopとセットでよく耳にするのですか?
答えは、hbaseがデータの保存にHDFSを使っているからです。
hbaseはリアルタイムにつよいスケーラブルなカラム思考NoSQLつまりデータベースです。
すべてのデータベースはそれ自体が保存対象に聞こえがちですが、すべてのデータベースにはファイルシステムが必要です。Hbaseは
HDFSをデータ保存のファイルシステムとして使っています。
これがHadoopとセットとされる理由です。ちなみにHadoopはMapReduceとHDFSの二つの要素の総称であることを忘れないように
してください。単純にHadoopというと、その構成要素のどちらをさしているのか、曖昧なとき話がふわっとします。違い意識して
語弊がない単語をえらびましょう。つまりは
最初に質問で「hbaseはなぜhadoopとセットでよく耳にするのですか?」というのはhbaseはデータ保存にHDFSを採用することで大量の
データを高速に扱うことに成功しているからです。
参考: https://www.quora.com/Does-HBase-use-Hadoop-to-store-data-or-is-a-separate-database-independent-of-Hadoop
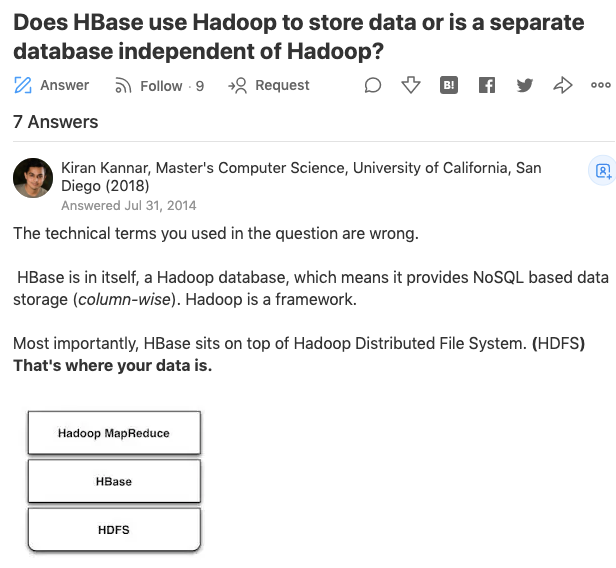
似たような質問にHbaseとHadoop/HDFSとの違いは?というのがstackoverflowにありその解答もとても
詳しく分かりやすいです。
https://stackoverflow.com/questions/16929832/difference-between-hbase-and-hadoop-hdfs
hbaseでよく目にするrandomアクセスとは?それはコンスタントな処理時間のこと
time complexityでいうとO(1)で処理できる
っていうことですね。そりゃそうですよ、だってhbaseなんてデカイHashMapなだけですから。
対象的にHDFSで 何か検索しようとすると、全検索っというのは分かりやすい対比です。
Hadoop uses distributed file system i.e HDFS for storing bigdata.But there are certain Limitations of HDFS and Inorder to overcome these limitations, NoSQL databases such as HBase,Cassandra and Mongodb came into existence.
Hadoop can perform only batch processing, and data will be accessed only in a sequential manner. That means one has to search the entire dataset even for the simplest of jobs.A huge dataset when processed results in another huge data set, which should also be processed sequentially. At this point, a new solution is needed to access any point of data in a single unit of time (random access).
出典: https://stackoverflow.com/questions/16929832/difference-between-hbase-and-hadoop-hdfs
そうなると、 Cassandraのデータ、ストレージはなに?
ローカルファイルシステムをつかてます。
詳しくは、まず、このqiita記事で
データベースを考えることにおいて最重要要素が三つあったことを復讐させられる
CAP定理です。
そうした時に、HbaseとCassandraでは、このCAPのトレードオフのどれを優先しているか?というコンセプトが
違うことがわかる。
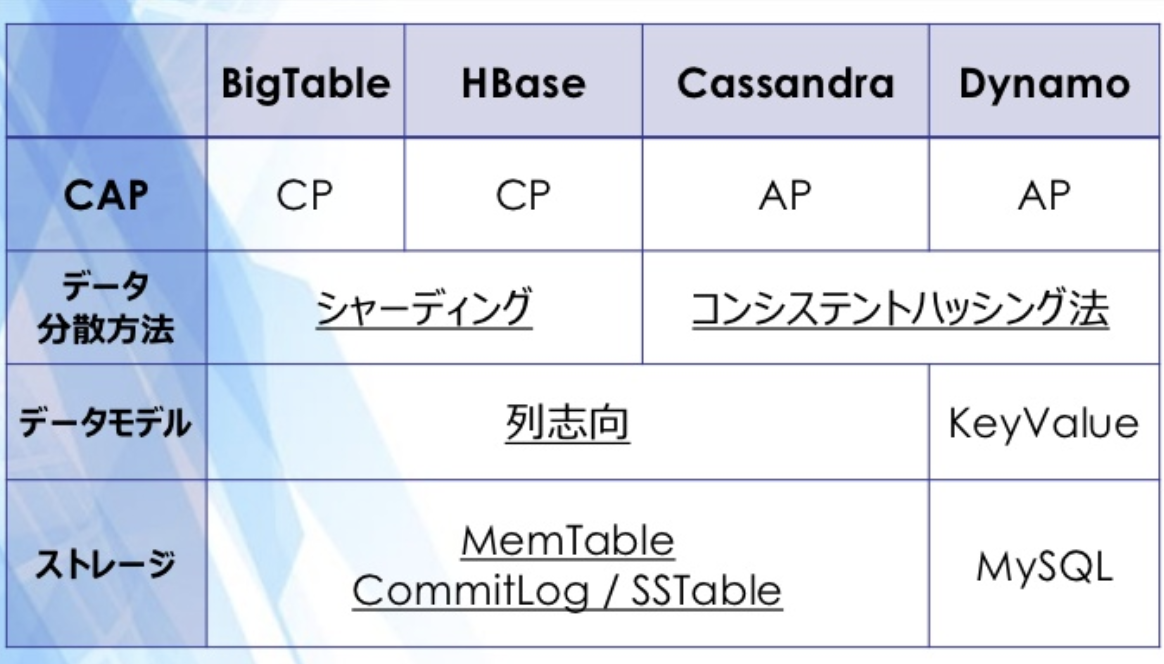
CP型のKVS:HBase
一時的なダウンタイムを許容することによって、強い一貫性と高い負荷分散性能を実現しているDataBase
AP型のKVS:Cassandra
強い一貫性を保てないことを許容するが、EventualConsistencyによってある程度の一貫性を保つ、高い可用性と高い負荷分散性能を実現しているDataBase
つまり、Aを優先しているCassandraはAPIなどの可用性をもとめるシステムに使われやすく、逆にAのないHbaseは裏側(バックエンド)で使われやすそう、という印象をもてる。また一貫性(C)にかんしては、Hbaseが高いということがわかる。
あらためてデータベースの技術選定においてCAP定理は非常に重要な判断基準で、学びが深い見方である
Cassandraの仕組みを非常に詳しく説明されている。qiita記事 ファイルシステムは、KVSなのか?(HBase VS CassandraからわかるKVSの仕組み)
むずかしいですが、かいつまんでいうと
CassandraはConsistet Hashing をつかっています。ノード間同士で直接はなす、Gossip Protocol(ゴシッププロトコル)とい方法でゆるく情報交換しています。さらに、Quorum Protocol(クォーラムプロトコル)で一貫性をある程度保っています。まぁ、Gossipつかっているのでマスター(Master)ノードたるもんが必要ありませんので、可用性は高い!ということになります。さらにHbaseとちがってファイルシステムはローカルのファイルシステムを使っています。
ちなみにHbaseの分割方法はkeyのレンジでわけるSharding(シャーディング)です。Consistent Hashingとセットで覚えておきましょう。
結局列思考型も、KVSと考えると
シンプルでわかりやすい。 (slide 16/67)
一通り理解したあと、この図はスッキリ理解できます。(このスライドp37)
かんたんなまとめコメント
私が感じたのは
Hbaseはgossipe + CHで(強調)分散してるので、CAPの C(onsistency)が弱めの sorted 辞書
ということがわかった。
CFはどちらかというと管理目的でつくられており、基本はRow, Columnの関係でかんがえてよし。
でか目のデータで、ユーザーごとに属性を保存しておきたというユースケースは辞書を更新していくだけなのでぴったりだと思う。
あと、NoSQLなのですでに非正規化された状態でデータを想定することが大事。
ユーザーの行動履歴とか、時系列で増えていくイベントに対しては、管理するだけなら、rowkeyにCQをどんどこ追加していくだけで
住むが、そうでない場合は,時間をcolumnに加えると、やたらカラムが増えて、結局処理が大変になりそうだ。という印象です。
以上です