表題は
shardingとpartitioningの違いは?
ですが、サブタイトルは
partitioningを正しく理解すると自ずとshardingが理解できる
です。
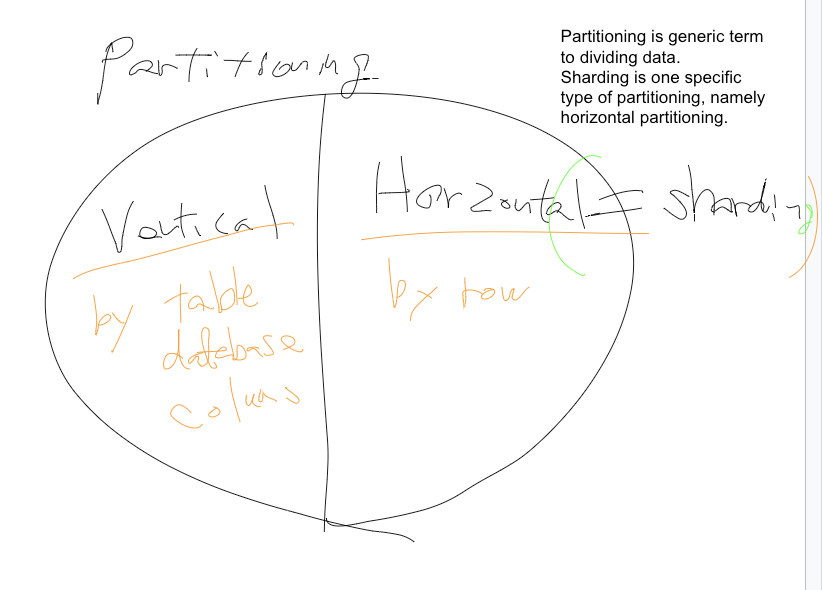
シャーディングとパーティショニングの違いは
パーティショニングはもっと
分散コンピューティングにおいて一般的な用語でデータベースのデータ分ける事です。
データの分け方もいろいろあって
そもそもあるシステムのデータベースAはhost1に、データベースBはhost2に持たすや、テーブルA~Eはhost1に、のように分ける方法は
Vertical partitioningといいいます。
反対にHorizontal partitioingというものあります。
これがshardingです。特別にというか、horizontal partitioningは別名が付いているだけです。
で、horizontalは、同じテーブルでも、行ごとにhostを分ける考え方です。
例えばユーザーというテーブルが有ったときに
Aから始まる名前のユーザーはhost1に、
Bから始まる名前のユーザーはhost2に、
という要領で分ける(partritioningする)方法です。
このshardingの場合、ホットスポットをつくる場合があります。ホットスポットとは分散において、あると特定のhostにデータが集中してしますことです。
以下にここまでのおさらいの図をいれます。
Partitioning by application side アプリケーションがデータがどのホストにあるか特定しないといけない。
- Redis, Memcache, kyotoTycoon
Partitioning by database side データベース側でデータがどのホストにあるか管理しているので、アプリケーションは基本、データがどこに存在しているかを意識しなくてよい。
- Cassandara, MongoDb, Hbase, Hadoop
分散コンピューティングにおけるPartitioningの問題点
・ノードを増やしたときに、リバランスが必要
・ホットスポットがでてしまう
・Joinが計算コストが高い
なので、できることなら、分散(partitoining)しないでも行けないか
考えてみて、やはりデータ量の問題から分散しないといけないときは
Partitioningを考えましょう。
Consistent Hashingとはpartitioningを一種です。
まず、partitioningのおさらいで
databaseやtableごとに分ける方法、
user idのhash(user id)で分けるようなhash&modな方法が
思いつく方法です。
hash&modな方法だとノードを増やしたときのレバランスが
全ノードに対して発生します。それを改善したのが
consistent hashingで、範囲を予めホスト間で決めておくという
ものです。範囲hashingといってもいいでしょう。
以上です
参考参照:
動画Sharding & Database Partitioning | System Design Basics
stack overflow database sharding vs partitioning