こんにちは
sparkをしばらく触ってきて、パフォーマンスの出すためのポイントやハマり
ポイントを未然に防ぐチップを箇条書きします。
spark関連のチップ
・spark2.3以降ならKryoSerializerをつかうとJVMでのデータコピーが速い
・spark本家のチューニングを読む

・もちろんcollectなどのアクションは大量のデータに対して行わない。
・driverとexecutorを意識する
・無駄にnum_executorを上げるならdynamic allocationも検討しよう
・nullの扱い spark 機械学習でnull valueの扱い
・joinの注意点 spark join で気をつけたほうが良い点 (null値を含んだjoin)
・spark よく出るエラー LiveListenerBus とRejectedExecutionException
・ML 基礎 spark ML pipelineの基礎
パフォーマンスの上げ方
・そもそも、大きなアーキテクチャでhbaseとか導入できないか?なぜ?
・stagesを少なくできないか?
・shuffle時の通信量を小さくできないか?
・Explainでさらにボトルネックをさくる
・RDDじゃなくてdataframeを極力つかう
spark SQLのexplainの読み方
これでUIの読み方だいたいしる。
explainの意味をしる
databricks社のエンジニアさんの解説、作っている人の話は確かそう
このスライドは必見です。
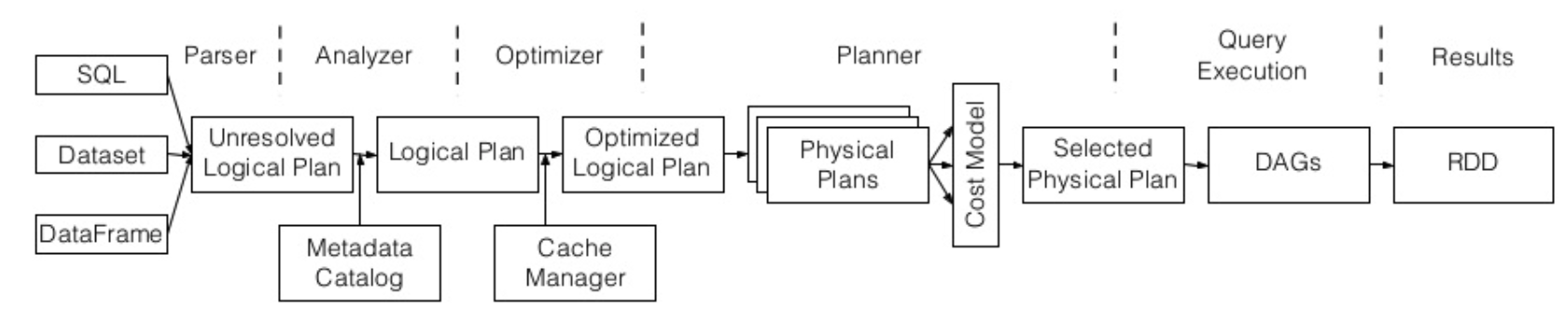
queryはハイレベルでqueryのプランニングでjobは詳細なstageとtaskって感じ

あとはグーグル検索でのヒットの一位だったのでこちら
以上です
参考参照:
Apache Spark の Physical/Logical plan の解説を試みる https://qiita.com/moomindani/items/19eb15012cb4d4aaf4b6
Sparkの内部処理を理解する https://qiita.com/uryyyyyyy/items/ba2dceb709f8701715f7
Apache Sparkコミッターが教える、Spark SQLの詳しい仕組みとパフォーマンスチューニング Part1 https://logmi.jp/tech/articles/321474